Rvest and SelectorGadget
I recently discovered rvest and SelectorGadget as a way to scrape data from websites easily. This is a follow up to a previous post here about how I obtained the data.
Introduction
The goal is to scrape the win/loss information for each player’s champion selection from the 2013-2015 NA/EU LCS season. To do this SelectorGadget can be used to get the required information to feed into rvest and get the highlighted information.
Import Site
To do this, readLines and HTMLTreeParse was used to import the site.
library(rvest)
library(XML)
website <- "http://lol.gamepedia.com/2015_NA_LCS_Summer/Scoreboards/Regular_Season/Week_1"
getWebsite <- function(webpage) {
webpage <- readLines(tc <- textConnection(webpage)); close(tc)
pagetree <- htmlTreeParse(webpage, error=function(...){}, useInternalNodes = TRUE)
return(pagetree)
}
pagetree <- getWebsite(website)Teams
The first thing is to get what teams played during the week, to do this we can highlight the selected regions of interest and deselect regions that are of no interest.
This gives the path selection as tr+ tr th:nth-child(4), tr+ tr th:nth-child(1) to be used with html_nodes.
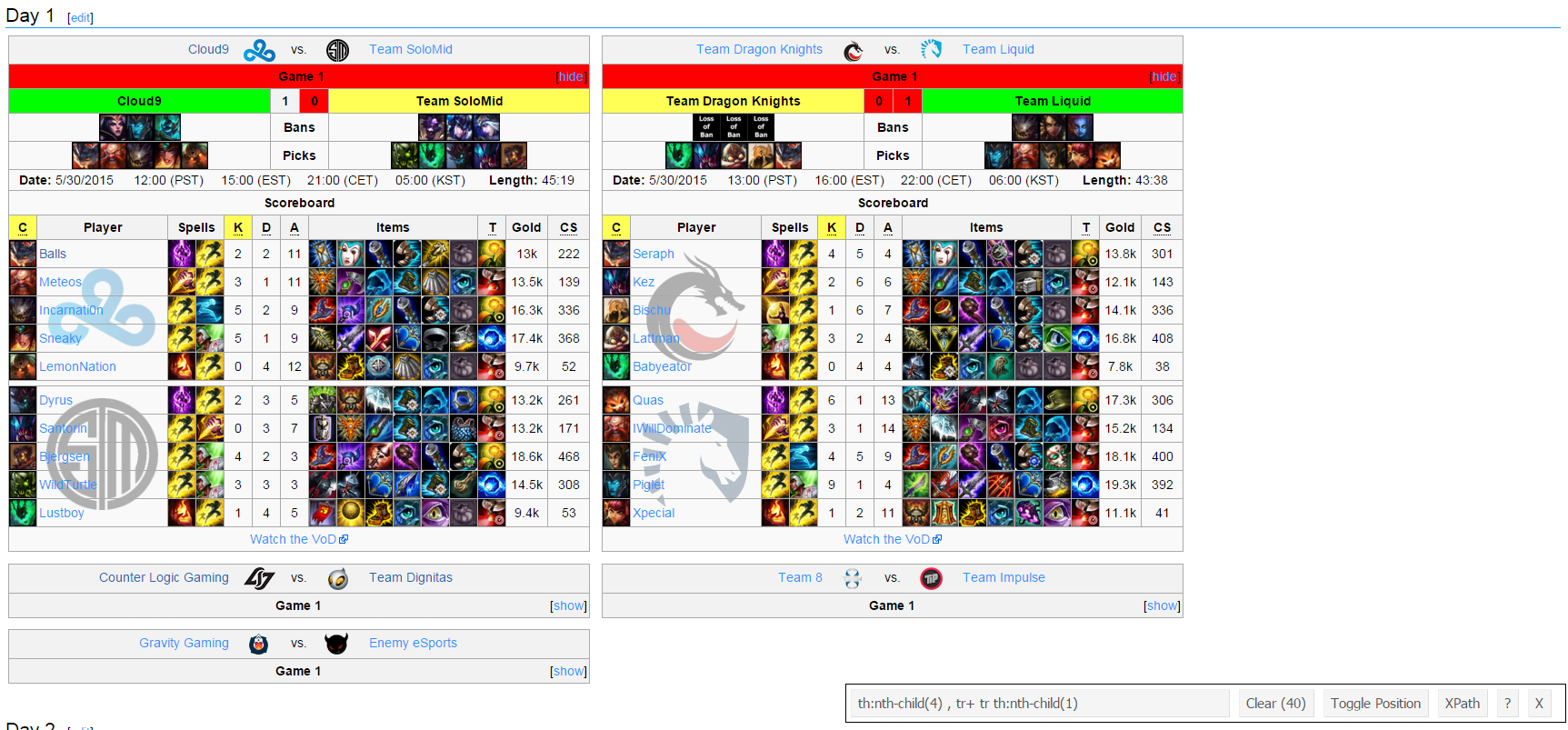
tr <- html_text(html_nodes(pagetree, "tr+ tr th:nth-child(4), tr+ tr th:nth-child(1)"))
head(tr)## [1] "Cloud9\n" "Team SoloMid\n" "C\n"
## [4] "K\n" "Team Dragon Knights\n" "Team Liquid\n"From this, we get the extra values of “C” and “K” and the new line character need to be removed. League of Legends incorporates 5 players to a team, so each team name is going to be repeated 5 times.
getTeams <- function(pagetree) {
tr <- html_text(html_nodes(pagetree, "tr+ tr th:nth-child(4), tr+ tr th:nth-child(1)"))
team.other <- gsub("\n", "", tr)
team <- team.other[team.other != "C" & team.other != "K"]
team <- rep(team, each=5)
return(team)
}Player and Champion
This requires more work. The easiest way to do this was to grab the table and using the design of the 1st and 2nd value being champion followed by player name. Originally, we get the table and then extract the data into lists. This is because the number of items bought per game is unknown as well as the trinkets was only introduced in the 2014 season.
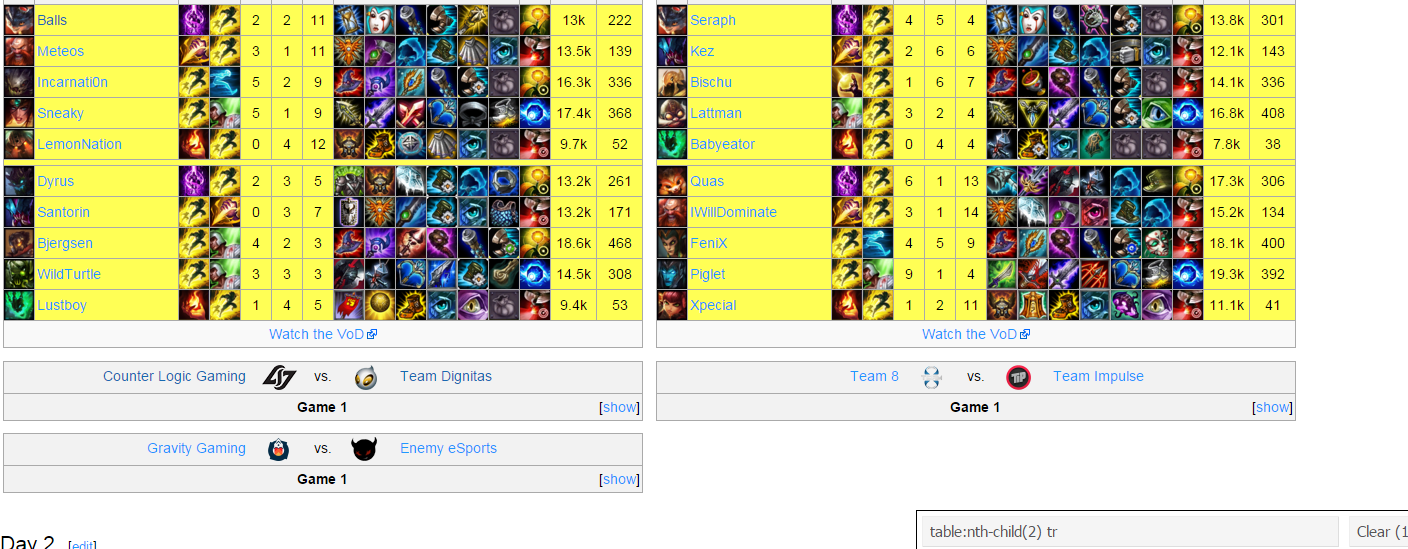
nodes <- html_nodes(pagetree, "table:nth-child(2) tr")
head(nodes)## [[1]]
## <tr><th style="width:30px; padding:0"><abbr title="Champion">C</abbr>
## </th>
## <th>Player
## </th>
## <th colspan="2" style="width:61px; padding:0">Spells
## </th>
## <th style="width:25px"><abbr title="Kills">K</abbr>
## </th>
## <th style="width:25px"><abbr title="Deaths">D</abbr>
## </th>
## <th style="width:25px"><abbr title="Assists">A</abbr>
## </th>
## <th colspan="6" style="width:185px; padding:0">Items
## </th>
## <th style="width:30px; padding:0"><abbr title="Trinket">T</abbr>
## </th>
## <th style="width:40px">Gold
## </th>
## <th style="width:40px"><abbr title="Creeps slain">CS</abbr>
## </th></tr>
##
## [[2]]
## <tr><td style="padding:0; height:30px"><a href="/Rumble" title="Rumble" class="mw-redirect"><span class="sprite champion-sprite sprite-size-30" style="background-position:-120px -210px"><br/></span></a>
## </td>
## <td style="text-align:left"><a href="/Balls" title="Balls" class="mw-redirect">Balls</a>
## </td>
## <td style="padding:0"><a href="/Teleport" title="Teleport"><span class="sprite summoner-spell-sprite sprite-size-30" style="background-position:-180px -0px"><br/></span></a>
## </td>
## <td style="padding:0"><a href="/Flash" title="Flash"><span class="sprite summoner-spell-sprite sprite-size-30" style="background-position:-120px -30px"><br/></span></a>
## </td>
## <td>2
## </td>
## <td>2
## </td>
## <td>11
## </td>
## <td style="padding:0"><a href="/Zhonya%27s_Hourglass" title="Zhonya's Hourglass"><span class="sprite item-sprite sprite-size-30" style="background-position:-330px -300px"><br/></span></a>
## </td>
## <td style="padding:0"><a href="/Liandry%27s_Torment" title="Liandry's Torment"><span class="sprite item-sprite sprite-size-30" style="background-position:-0px -270px"><br/></span></a>
## </td>
## <td style="padding:0"><a href="/Void_Staff" title="Void Staff"><span class="sprite item-sprite sprite-size-30" style="background-position:-420px -180px"><br/></span></a>
## </td>
## <td style="padding:0"><a href="/Sorcerer%27s_Shoes" title="Sorcerer's Shoes"><span class="sprite item-sprite sprite-size-30" style="background-position:-60px -180px"><br/></span></a>
## </td>
## <td style="padding:0"><a href="/Blasting_Wand" title="Blasting Wand"><span class="sprite item-sprite sprite-size-30" style="background-position:-90px -60px"><br/></span></a>
## </td>
## <td style="padding:0"><span class="sprite item-sprite sprite-size-30" style="background-position:-540px -0px"><br/></span>
## </td>
## <td style="padding:0"><a href="/Greater_Totem" title="Greater Totem"><span class="sprite item-sprite sprite-size-30" style="background-position:-30px -30px"><br/></span></a>
## </td>
## <td>13k
## </td>
## <td>222
## </td></tr>
##
## attr(,"class")
## [1] "XMLNodeSet"From this the href value can be obtained and the title attribute can be obtained per line. In order to deal with data that may not come from a game, each player must pick a summoner spell. This is checked to determine if it is a player and not another field.
getPlayerChamp <- function(pagetree) {
nodes <- html_nodes(pagetree, "table:nth-child(2) tr")
hrefs <- lapply(nodes, html_nodes, "td a")
# Need to remove some that are way to long that dont fit the profile on some pages (nested table tiebreaker). These are large values so easy to remove
hrefs <- hrefs[which(sapply(hrefs, length) < 15)]
titles <- lapply(hrefs, html_attr, "title")
# remove values that do not have a summoner as the 3rd value
sum.spell <- c("Flash", "Heal", "Ignite", "Teleport", "Smite", "Exhaust", "Ghost", "Cleanse", "Barrier")
titles <- titles[(unlist(lapply(titles, "[", 3)) %in% sum.spell)]
# Get champion and player
champ.player <- unlist(lapply(titles, "[", 1:2))
champ.player <- champ.player[!is.na(champ.player)]
return(champ.player)
}
head(getPlayerChamp(pagetree))## [1] "Rumble" "Balls" "Gragas" "Meteos" "Kog'Maw"
## [6] "Incarnati0n"#####Win/Loss
To get win/loss, the path tr+ tr th:nth-child(3) , tr+ tr th:nth-child(2) was used. Again to follow how the data is to be set up, this is repeated 5 times.
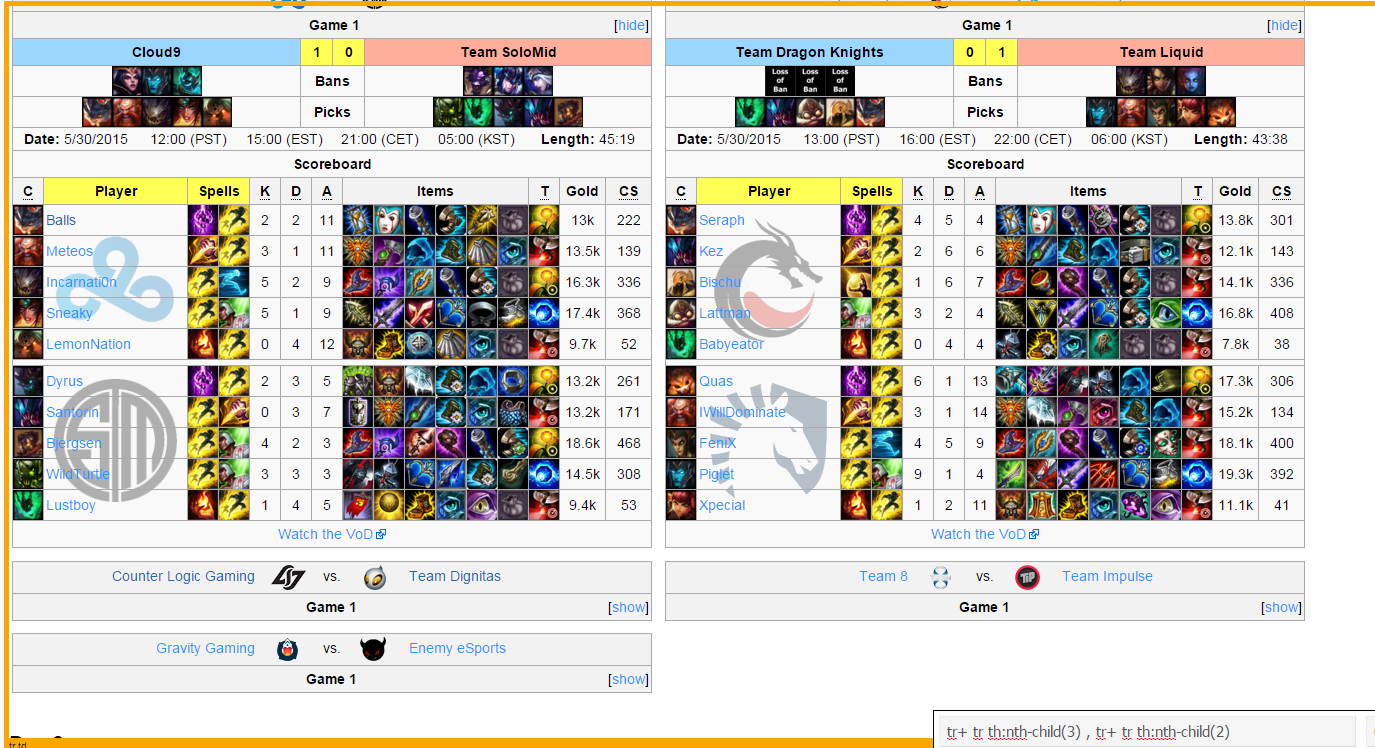
getWinLoss <- function(pagetree) {
wL <- suppressWarnings(as.numeric(html_text(html_nodes(pagetree, "tr+ tr th:nth-child(3) , tr+ tr th:nth-child(2)"))))
wL <- wL[!is.na(wL)]
wL <- rep(wL, each=5)
}
head(getWinLoss(pagetree))## [1] 1 1 1 1 1 0####Date
To get the date, the path .match-recap tr:nth-child(1) td was used. Each value is from this line is found, so the Date: line must be found and replaced.
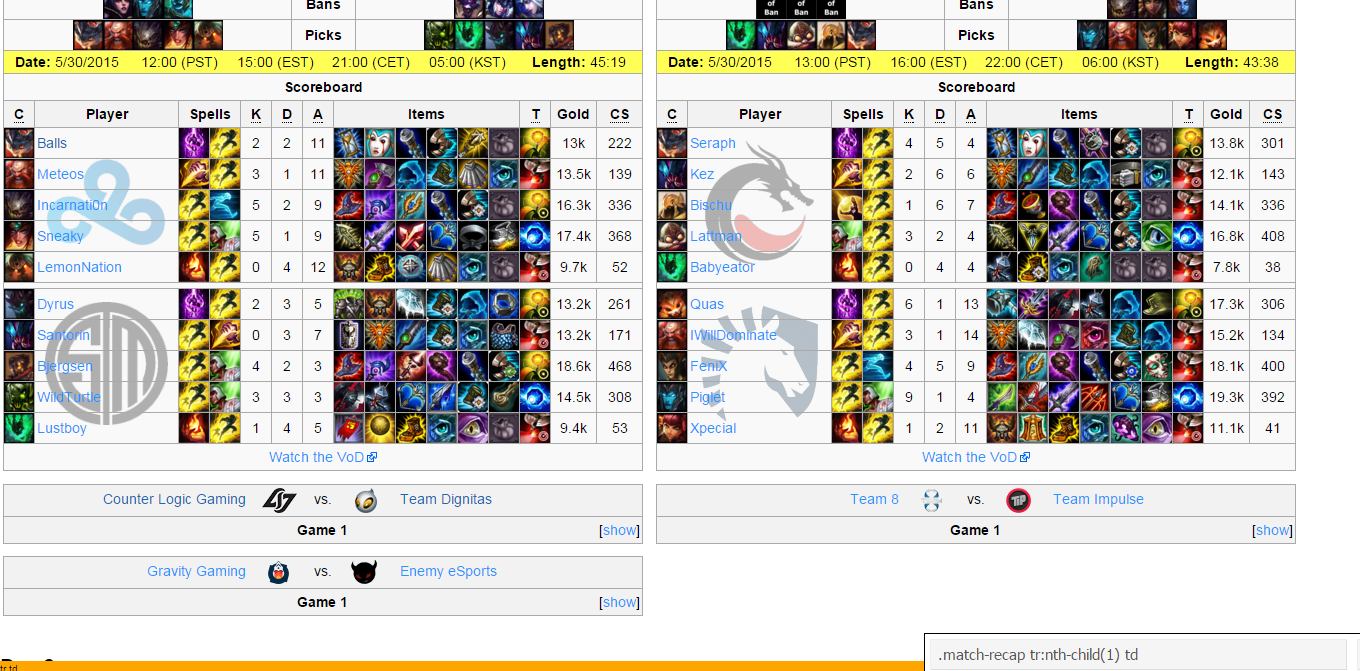
getDate <- function(pagetree) {
td <- html_nodes(pagetree, ".match-recap tr:nth-child(1) td")
text <- html_text(td)
text <- text[grepl("Date:", text)]
text <- gsub("\\s", "",gsub("Date:", "", text))
text <- rep(text, each=10)
return(text)
}
head(getDate(pagetree))## [1] "5/30/2015" "5/30/2015" "5/30/2015" "5/30/2015" "5/30/2015" "5/30/2015"Putting it together
In order to put this together, the above functions are called and checked to make sure that data is of the same length to combine it to a data frame.
Missing data is generally shown as one of the above not being of the same length and since this is a wiki, they could be fixed by adding the required information. With missing information, the function and webpage will be shown as a warning to check what information is missing from the site.
makeDF <- function(website) {
pagetree <- getWebsite(website)
champ.player <- getPlayerChamp(pagetree)
p.champ <- data.frame(player=champ.player[seq(2,length(champ.player),2)],
champ=champ.player[seq(1,length(champ.player), 2)], stringsAsFactors=F)
team <- getTeams(pagetree)
if (length(team) != nrow(p.champ)) {
warning(paste("Error with team on", website))
return(NA)
} else {
p.champ$team <- team
}
wL <- getWinLoss(pagetree)
if (length(wL) != nrow(p.champ)) {
warning(paste("Error with win loss on", website))
return(NA)
} else {
p.champ$wL <- wL
}
date <- getDate(pagetree)
if (length(date) != nrow(p.champ)) {
warning(paste("Error with date on", website))
return(NA)
} else {
p.champ$date <- date
}
return(p.champ)
}
singlePage <- makeDF(website)
dim(singlePage)## [1] 100 5kable(head(singlePage), row.names=F, align='c')| player | champ | team | wL | date |
|---|---|---|---|---|
| Balls | Rumble | Cloud9 | 1 | 5/30/2015 |
| Meteos | Gragas | Cloud9 | 1 | 5/30/2015 |
| Incarnati0n | Kog’Maw | Cloud9 | 1 | 5/30/2015 |
| Sneaky | Sivir | Cloud9 | 1 | 5/30/2015 |
| LemonNation | Nautilus | Cloud9 | 1 | 5/30/2015 |
| Dyrus | Maokai | Team SoloMid | 0 | 5/30/2015 |
Using this, a vector of websites can be computed such as:
# Create vector of websites
webpage.NA.2015.spring <- paste0("http://lol.gamepedia.com/2015_NA_LCS_Spring/Scoreboards/Round_Robin/Week_", 1:9)
# Function to take websites and form one data frame
getInfo <- function(website) {
return(do.call("rbind", lapply(website, makeDF)))
}
NA.2015.spring <- getInfo(webpage.NA.2015.spring)
dim(NA.2015.spring)## [1] 920 5kable(head(NA.2015.spring), row.names=F, align='c')| player | champ | team | wL | date |
|---|---|---|---|---|
| Dyrus | Irelia | Team SoloMid | 1 | 2015-01-24 |
| Santorin | Rek’Sai | Team SoloMid | 1 | 2015-01-24 |
| Bjergsen | Ahri | Team SoloMid | 1 | 2015-01-24 |
| WildTurtle | Jinx | Team SoloMid | 1 | 2015-01-24 |
| Lustboy | Janna | Team SoloMid | 1 | 2015-01-24 |
| Balls | Gnar | Cloud9 | 0 | 2015-01-24 |
Conclusion
Using this, it can be combined to form a final data format and looped over to gather all the data. There are a few things not shown here, such as standardizing the dates, checking for misspelled player names (Dyrus/Dryus), players not updated (SELFIE NO PAGE FOUND, SELFIE), and fixing bo3/5 series where wins are not 0 or 1 but can be 0-5.