Tim Hortons and Starbucks in Canada using Open Street Map
Introduction
In Canada, there really only seems to be two coffee chains, Tim Hortons and Starbucks. Each chain has fiercly loyal costumers and almost impossible to drive anywhere without seeing one or both dotting the streets and malls. This led to the question of where and how many of each are there in Canada.
Data
In order to locate Tim Hortons and Starbucks, Open Street Map (OSM) data was used. Specifically the Canada extract from GeoFabrik last modified on 2015-12-31T20:14:02Z.
Data Extraction
As in previous posts 1, 2, RPostgreSQL package will be used to connect to the database.
library(RPostgreSQL)
# Connect to database
m <- dbDriver("PostgreSQL")
con <- dbConnect(m, dbname="gis")In order to get the list, the planet_osm_point table should be queried for partial matches to Starbucks and Tim Hortons. The names are set to uppercase for both to partial match search and values in table so letter case is not an issue. As well, the amenity should exist so that it is a cafe, restaraunt, or exists.
q <- "SELECT p.name AS name, p.amenity AS amenity, ST_X(ST_Transform(way, 4326)), ST_Y(ST_Transform(way,4326))
FROM planet_osm_point p
WHERE (UPPER(p.name) LIKE UPPER('%Starbuck%') OR UPPER(p.name) LIKE UPPER('%Tim H%'))
AND p.amenity IS NOT NULL;"
cLoc <- dbGetQuery(con, q)
# Show data
kable(rbind(head(cLoc), tail(cLoc)), align='c')| name | amenity | st_x | st_y | |
|---|---|---|---|---|
| 1 | Tim Hortons | fast_food | -114.6626 | 51.79412 |
| 2 | Starbucks | cafe | -114.4748 | 51.18928 |
| 3 | Tim Hortons | cafe | -114.4725 | 51.18484 |
| 4 | Tim Hortons | restaurant | -114.4636 | 49.62061 |
| 5 | Starbucks | cafe | -114.2468 | 51.12408 |
| 6 | Tim Hortons | restaurant | -114.2400 | 51.10743 |
| 1938 | Tim Horton’s | cafe | -115.5760 | 51.18011 |
| 1939 | Starbucks | cafe | -115.5710 | 51.17814 |
| 1940 | Starbucks | cafe | -115.5553 | 51.14796 |
| 1941 | Tim Horton’s | cafe | -115.3621 | 51.10262 |
| 1942 | Starbucks | cafe | -115.3576 | 51.09280 |
| 1943 | Starbucks | cafe | -115.0585 | 49.51497 |
The last part of the data to extract is Canadian boarders of each province.
q2 <- "SELECT (dp).path[1] AS region, (dp).path AS index, ST_Y((dp).geom) AS lat, ST_X((dp).geom) AS lon
FROM (SELECT ST_DumpPoints(ST_Transform(ST_Collect(way), 4326)) AS dp
FROM planet_osm_line where boundary='administrative' and admin_level = '4') AS foo
ORDER BY index;"
cb <- dbGetQuery(con, q2)Data Clean Up
The data should be checked to make sure that the Tim Hortons and Starbucks are what we want.
unique(cLoc$amenity)## [1] "fast_food" "cafe" "restaurant" "toilets"Well, toilets should be checked to see if it is a Tim Hortons or not.
cLoc[cLoc$amenity == "toilets",]## name
## 860 150 King W Sun Life Financial PATH toilet behind Tim Hortons under escalator
## amenity st_x st_y
## 860 toilets -79.38467 43.64788This will need to be removed, seems very specific instructions for finding the toilet location as well.
cLoc <- cLoc[cLoc$amenity != "toilets",]The last thing to check is the names:
unique(cLoc$name)## [1] "Tim Hortons"
## [2] "Starbucks"
## [3] "Starbuck's"
## [4] "Starbucks Coffee"
## [5] "Tim Hortons Express"
## [6] "Tim Horton's"
## [7] "Tim Horton"
## [8] "Tim Hortons in Walmart"
## [9] "Tim Horton's Komoka"
## [10] "Tim Hortons Drive thru only"
## [11] "Tim Hortons @ Mini Mac"
## [12] "Tim Hortons @ MUSC"
## [13] "Tim Hortons/Wendy's"
## [14] "Wendy's/Tim Hortons"
## [15] "On The Run/Tim Hortons"
## [16] "On the Go Featuring: Tim Hortons Coffee & Baked Goods"
## [17] "Wendy's / Tim Hortons"
## [18] "Tim Hortons "
## [19] "Tim Horton`s"
## [20] "Tim Horton's Drive Thru"
## [21] "Café Starbucks"
## [22] "Starbucks coffee"
## [23] "Café Starbucks Coffee"
## [24] "Café Starbucks Coffee Peel"
## [25] "tim Hortons"
## [26] "TIM HORTONS"
## [27] "Starbuck"
## [28] "starbucks"
## [29] "Tim Horton's Drive-thru"
## [30] "Wendy's / Tim Horton's"
## [31] "Starbucks "This looks good.
The last part is to identify each Tim Hortons and Starbucks to make it easier to plot and count. With 0 for Starbucks and 1 for Tim Hortons.
cLoc$identity <- NA
cLoc$identity[grepl(toupper("Star"), toupper(cLoc$name))] <- 0 # Set for Starbucks
cLoc$identity[grepl(toupper("Tim Hort"), toupper(cLoc$name))] <- 1 # Set for Tim HortonsPlot
regions <- cb
plot(x="", xlim=c(-140,-52), ylim=c(43,63), xlab="Longitude", ylab="Latitude", main="Tim Horton and Starbucks Locations from OSM Data")
uRegions <- unique(regions$region)
# Probably can be done without the loop
for (k in 1:length(uRegions)) {
theRegion <- uRegions[k]
lines(regions$lon[regions$region == theRegion], regions$lat[regions$region == theRegion])
}
# Add points
points(cLoc$st_x[cLoc$identity == 1], cLoc$st_y[cLoc$identity == 1], lwd=0.5, col=rgb(red=0, green=0, blue=255, alpha=255, max=255), pch=20)
points(cLoc$st_x[cLoc$identity == 0], cLoc$st_y[cLoc$identity == 0], lwd=0.5, col=rgb(red=255, green=0, blue=0, alpha=55, max=255) , pch=20)
legend("bottomleft", legend=c("Starbucks", "Tim Hortons"), col=c(2,4), pch = c(20,20))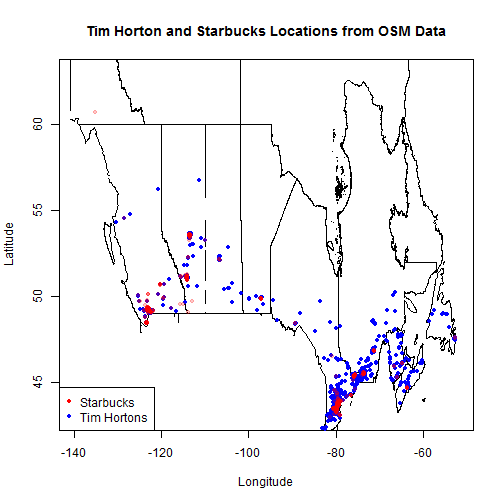
Summary
The number of Starbucks location from OSM Data in Canada is: 677
The number of Tim Hortons location from OSM Data in Canada is: 1265
According to OSM data, there is nearly twice as many Tim Hortons locations in Canada. Where as Starbucks tends to be located around city centers, Tim Hortons seems to be dotted around Canada.
Issues
Since OSM data is crowd sourced, it may be that Tim Hortons locations are recorded more more often than Starbucks. Again, with crowd sourced data, Tim Hortons or Starbucks may not be properly represented in smaller cities and towns. Another issue is setting amenity to be not null, we may have missed some that were not tagged.